- 概要
-
統計モデルは、誤差を含むデータの背後にある規則性、そのようなデータを発生させる仕組みを数式で表したものである。統計モデルにより誤差を含む観測データから現象を分析したり、予測を行うことができる。代表的な統計モデルとパラメタの推定法について解説する。
【キーワード】
統計モデル,回帰モデル,パラメタ推定,最小二乗法,尤度,最尤推定法
- 放送授業パタン,台本(字幕代りにどうぞ)
-
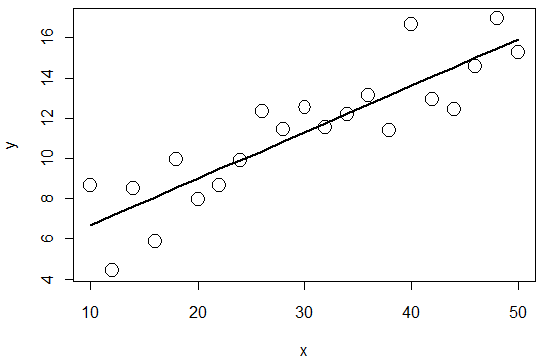
- Rによる線形単回帰モデルの推定
# データ(x, y)の発生
> x <- seq(10, 50, by=2)
> x
[1] 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38 40 42 44 46 48 50
> y <- 0.3*x + 3 + 2*rnorm(length(x)) # rnormは標準正規分布に従う乱数
> y
[1] 8.663067 4.417241 8.482272 5.863328 9.957464 7.937999 8.631248
[8] 9.945805 12.372738 11.459144 12.535264 11.563675 12.204745 13.157904
[15] 11.416149 16.668952 12.952537 12.454415 14.586408 16.933919 15.277438
# 線形単回帰モデルの当てはめ y = beta0 + beta1*x + epsilon
> reg <- lm(y ~ x)
> reg
Call:
lm(formula = y ~ x)
Coefficients:
(Intercept) x
4.3749 0.2311
# beta0 = 4.3749, beta1 = 0.2311
#
> summary(reg)
Call:
lm(formula = y ~ x)
Residuals:
Min 1Q Median 3Q Max
-2.73114 -1.05939 -0.02841 1.22661 3.04904
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 4.37487 0.92325 4.739 0.000143 ***
x 0.23113 0.02854 8.099 1.40e-07 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 1.584 on 19 degrees of freedom
Multiple R-squared: 0.7754, Adjusted R-squared: 0.7636
F-statistic: 65.6 on 1 and 19 DF, p-value: 1.395e-07
# モデルによるyの推定
> yp <- predict(reg)
> yp
1 2 3 4 5 6 7
6.686131 7.148384 7.610636 8.072888 8.535140 8.997392 9.459644
8 9 10 11 12 13 14
9.921897 10.384149 10.846401 11.308653 11.770905 12.233157 12.695409
15 16 17 18 19 20 21
13.157662 13.619914 14.082166 14.544418 15.006670 15.468922 15.931175
> plot(x, y, cex=2)
> lines(x, yp, lwd=2)
>
- Rによる線形重回帰モデルの推定
# データ(x1, x2, y)の発生
> x1 <- rnorm(25)
> x2 <- rnorm(25)
> y <- -2*x1 + 3*x2 + rnorm(25)
> cbind(x1, x2, x3)
以下にエラー cbind(x1, x2, x3) : オブジェクト 'x3' がありません
# データ(x1, x2, y)を見る
> cbind(x1, x2, y)
x1 x2 y
[1,] -0.61277113 1.53369091 5.7037729
[2,] 0.61270239 0.18043403 -2.4805156
[3,] 0.86204310 -0.59110891 -3.1292688
[4,] 0.14932451 0.70890945 -0.2116559
[5,] -0.88492421 0.20149391 1.6569176
[6,] -0.15321895 -1.13054300 -3.5558333
[7,] -0.16752711 0.49295931 2.4872306
[8,] 0.38367684 -0.49557616 -2.3856437
[9,] 1.14786089 1.12382978 1.6855482
[10,] -0.21587774 0.06164808 1.9278484
[11,] 0.60269063 1.36783261 2.4787415
[12,] -1.16329074 0.65307595 3.3426050
[13,] 0.78059385 0.12166385 -2.1424934
[14,] 0.78227176 0.91640460 -0.1091157
[15,] -1.37488675 0.33200965 3.8953782
[16,] -2.08050957 1.10514189 8.4184230
[17,] 0.14970812 1.47271473 3.2186818
[18,] -0.15843057 -0.88465590 -1.2376282
[19,] 1.00466817 -0.37580018 -4.1724577
[20,] -1.87898662 0.94161486 7.5163773
[21,] -0.39056906 0.18860614 2.0090421
[22,] -0.04010889 0.89328051 2.1255494
[23,] -0.98885464 -0.15011884 0.8197678
[24,] 0.93129664 -0.09585387 -1.3058274
[25,] -0.51396782 -0.27574255 1.6407800
# y = beta0 + beta1*x1 + beta2*x2 + epsilon を当てはめる
> reg <- lm(y ~ x1 + x2)
> reg
Call:
lm(formula = y ~ x1 + x2)
Coefficients:
(Intercept) x1 x2
-0.07336 -2.35576 2.70634
# beta0 = -0.07336, beta1 = -2.35576, beta2 = 2.70634
> summary(reg)
Call:
lm(formula = y ~ x1 + x2)
Residuals:
Min 1Q Median 3Q Max
-1.70507 -0.71529 -0.06723 0.65188 1.42153
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.07336 0.21075 -0.348 0.731
x1 -2.35576 0.21986 -10.715 3.39e-10 ***
x2 2.70634 0.26936 10.047 1.11e-09 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.9552 on 22 degrees of freedom
Multiple R-squared: 0.9222, Adjusted R-squared: 0.9151
F-statistic: 130.3 on 2 and 22 DF, p-value: 6.344e-13
>
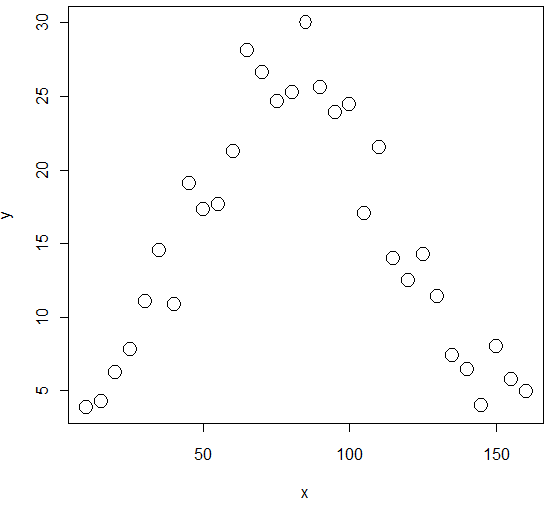
- Rによる非線形回帰モデルの推定
# データ(x, y)の発生
> x <- seq(10, 160, 5)
> x
[1] 10 15 20 25 30 35 40 45 50 55 60 65 70 75 80 85 90 95
[19] 100 105 110 115 120 125 130 135 140 145 150 155 160
> y <- 24*exp(-(x-80)^2/2000) + 3 + 2*rnorm(length(x)) # rnormは標準正規分布に従う乱数
> y
[1] 3.861066 4.276967 6.207594 7.829959 11.021070 14.527800 10.849562
[8] 19.144690 17.321895 17.679206 21.284289 28.145477 26.663816 24.702096
[15] 25.276374 30.044047 25.631026 23.917408 24.448038 17.075830 21.570455
[22] 13.932035 12.495133 14.210583 11.374660 7.395329 6.446238 4.003844
[29] 7.985488 5.749039 4.935011
> plot(x, y, cex=2)
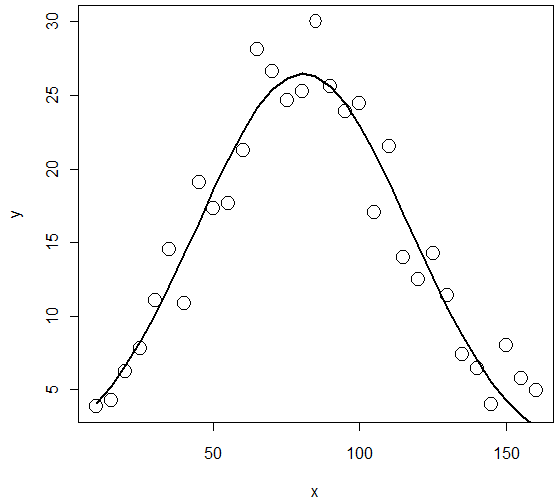
 # 非線形回帰モデル y = beta1*exp(-(x-beta2)^2/beta3^2 + epsilon を当てはめ,
# 最小二乗法でパラメタbeta1, beta2, beta3を推定
> reg <- nls(y ~ beta1*exp(-(x-beta2)^2/beta3^2), start=list(beta1=20, beta2=100, beta3=1000))
> reg
Nonlinear regression model
model: y ~ beta1 * exp(-(x - beta2)^2/beta3^2)
data: parent.frame()
beta1 beta2 beta3
26.49 80.56 -51.46
residual sum-of-squares: 147.1
Number of iterations to convergence: 12
Achieved convergence tolerance: 2.562e-06
# モデルによるyの推定
> yp <- predict(reg)
> yp
[1] 4.041368 5.225741 6.630815 8.256301 10.087965 12.095427 14.231096
[8] 16.430662 18.615353 20.696030 22.578877 24.172255 25.394025 26.178541
[15] 26.482494 26.288866 25.608512 24.479153 22.961907 21.135818 19.091045
[22] 16.921540 14.718027 12.562002 10.521257 8.647209 6.974030 5.519391
[29] 4.286453 3.266665 2.442927
> plot(x, y, cex=2)
> lines(x, yp, lwd=2)
>
# 非線形回帰モデル y = beta1*exp(-(x-beta2)^2/beta3^2 + epsilon を当てはめ,
# 最小二乗法でパラメタbeta1, beta2, beta3を推定
> reg <- nls(y ~ beta1*exp(-(x-beta2)^2/beta3^2), start=list(beta1=20, beta2=100, beta3=1000))
> reg
Nonlinear regression model
model: y ~ beta1 * exp(-(x - beta2)^2/beta3^2)
data: parent.frame()
beta1 beta2 beta3
26.49 80.56 -51.46
residual sum-of-squares: 147.1
Number of iterations to convergence: 12
Achieved convergence tolerance: 2.562e-06
# モデルによるyの推定
> yp <- predict(reg)
> yp
[1] 4.041368 5.225741 6.630815 8.256301 10.087965 12.095427 14.231096
[8] 16.430662 18.615353 20.696030 22.578877 24.172255 25.394025 26.178541
[15] 26.482494 26.288866 25.608512 24.479153 22.961907 21.135818 19.091045
[22] 16.921540 14.718027 12.562002 10.521257 8.647209 6.974030 5.519391
[29] 4.286453 3.266665 2.442927
> plot(x, y, cex=2)
> lines(x, yp, lwd=2)
>
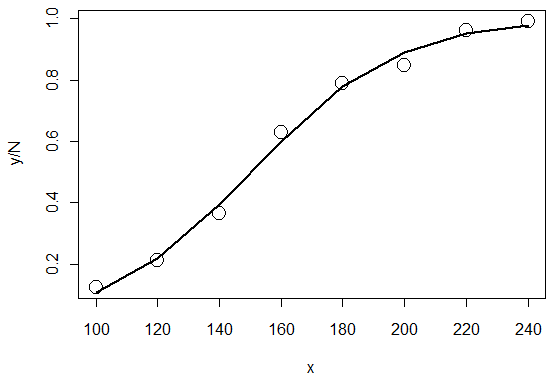
- Rによるロジスティック回帰モデルの推定
# 印刷教材 p.195 14.2.2 例3
# x 加熱温度
> x <- seq(100, 240, by=20)
# N サンプル数
> N <- c(96, 99, 99, 97, 100, 98, 99, 100)
# y 特性が変化したサンプル数
> y <- c(12, 21, 36, 61, 79, 83, 95, 99)
# (x, N, y)を見る
> cbind(x, N, y)
x N y
[1,] 100 96 12
[2,] 120 99 21
[3,] 140 99 36
[4,] 160 97 61
[5,] 180 100 79
[6,] 200 98 83
[7,] 220 99 95
[8,] 240 100 99
# ロジスティック回帰モデル
# N中yが特性変化する確率pは二項分布に従う
# 確率pは p(x|beta0, beta1) = 1/exp(-(beta0+beta1*x))と仮定
# パラメタbeta0, beta1を最尤法で推定
> reg <- glm(cbind(y, N-y) ~ x, family=binomial(link="logit"))
> reg
Call: glm(formula = cbind(y, N - y) ~ x, family = binomial(link = "logit"))
Coefficients:
(Intercept) x
-6.32272 0.04208
# beta0 = -6.32272, beta1 = 0.04208
Degrees of Freedom: 7 Total (i.e. Null); 6 Residual
Null Deviance: 385.3
Residual Deviance: 3.902 AIC: 40.96
> summary(reg)
Call:
glm(formula = cbind(y, N - y) ~ x, family = binomial(link = "logit"))
Deviance Residuals:
Min 1Q Median 3Q Max
-1.3018 -0.2721 0.3884 0.5431 0.9399
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -6.32272 0.45725 -13.83 <2e-16 ***
x 0.04208 0.00288 14.61 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 385.2569 on 7 degrees of freedom
Residual deviance: 3.9018 on 6 degrees of freedom
AIC: 40.957
Number of Fisher Scoring iterations: 4
> beta <- coef(reg)
> beta
(Intercept) x
-6.32272059 0.04207702
# pを計算する関数を定義
> p <- function(x,beta) {1/(1+exp(-(beta[1]+beta[2]*x)))}
> plot(x, y/N, cex=2)
> lines(x, p(x, beta), lwd=2)